In an era where digital experiences are increasingly tailored to individual preferences, recommendation systems have become the unsung heroes of our online interactions. From suggesting the next binge-worthy series on streaming platforms to curating personalized product recommendations in e-commerce, these systems work tirelessly behind the scenes to enhance our digital experiences. At the heart of many modern recommendation engines lies a powerful architecture known as the Two-Tower model. This article will take you on an comprehensive journey through the intricacies of the Two-Tower model, exploring its inner workings, applications, and the mathematics that drives its effectiveness.
The Essence of the Two-Tower Model
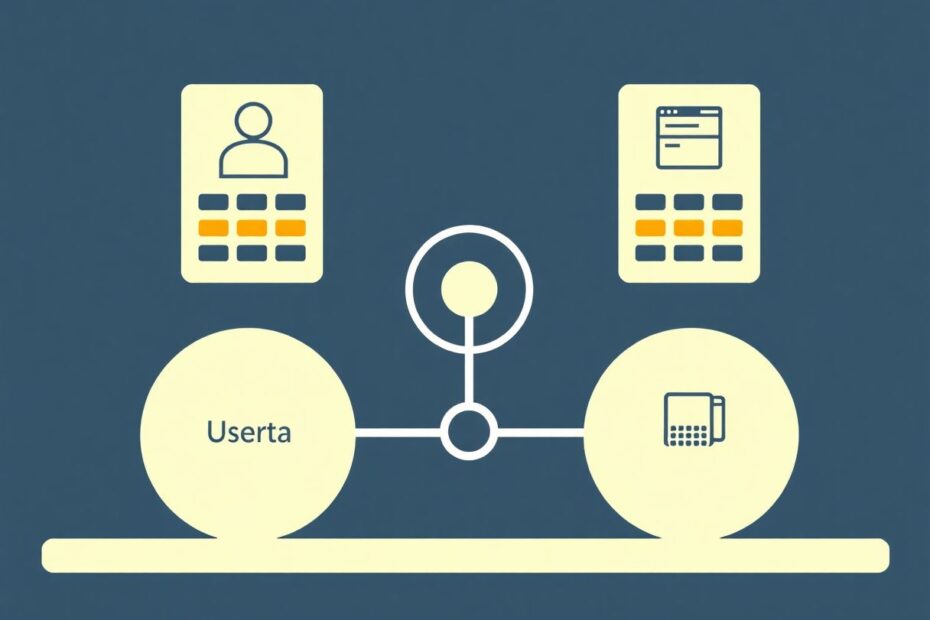
The Two-Tower model is a neural network architecture specifically designed for recommendation systems. Its name derives from its distinctive structure: two separate "towers" of neural networks that process user and item data independently. This elegant design allows for more flexible and scalable recommendations, especially when dealing with large-scale datasets involving millions of users and items.
Architectural Overview
The basic architecture of the Two-Tower model consists of three main components:
User Tower: This neural network processes user-related features and behaviors, such as demographics, browsing history, and past interactions.
Item Tower: This network handles item-specific characteristics and metadata, including product categories, content tags, and other relevant attributes.
Similarity Calculation: The outputs from both towers are compared to determine how well a user matches with an item, forming the basis for recommendations.
The Inner Workings of the Two-Tower Model
To truly understand the power of the Two-Tower model, let's break down its operation step by step:
Data Input and Feature Processing
The journey begins with data input. The User Tower receives user-specific features, while the Item Tower ingests item-related data. These inputs can be incredibly diverse, ranging from explicit user preferences to implicit behavioral signals.
Each tower employs deep neural networks to transform these raw features into high-dimensional embeddings. These embeddings are dense vector representations that capture complex patterns and relationships within the data. The neural networks typically consist of multiple layers, often including convolutional or recurrent layers depending on the nature of the input data.
Embedding Generation
The output of each tower is a compact, dense vector representation (embedding) for the user or item. These embeddings are the key to the model's efficiency and effectiveness. They distill vast amounts of information into a format that allows for rapid similarity calculations.
Similarity Calculation
Once the embeddings are generated, the model calculates a similarity score between the user and item embeddings. This score represents how likely the user is to be interested in the item. The choice of similarity metric is crucial and can significantly impact the model's performance.
Recommendation Generation
Items with the highest similarity scores are then recommended to the user. This process can be fine-tuned based on various business rules or constraints, such as diversity requirements or inventory availability.
The Mathematics of Similarity: Cosine vs. Euclidean
The choice of similarity metric is a critical decision in implementing a Two-Tower model. Two commonly used metrics are cosine similarity and Euclidean similarity. Let's delve deeper into these mathematical concepts:
Cosine Similarity: Measuring Directional Alignment
Cosine similarity measures the cosine of the angle between two vectors, providing a measure of their directional similarity. It's defined mathematically as:
cos(θ) = (A · B) / (||A|| ||B||)
Where A and B are the user and item embeddings, · represents the dot product, and ||x|| denotes the magnitude of vector x.
Cosine similarity offers several advantages:
- Its range is bounded between -1 and 1, making it easy to interpret.
- It's insensitive to the magnitudes of the vectors, focusing purely on their directional alignment.
- It performs well with high-dimensional and sparse data, making it suitable for recommendation tasks.
However, cosine similarity may not capture absolute differences between vectors effectively, which can be a limitation in certain scenarios.
Euclidean Similarity: Capturing Absolute Differences
Euclidean similarity is based on the negative Euclidean distance between vectors:
similarity = -||A - B||
This metric offers a different perspective:
- It captures absolute differences between vectors, which can be crucial in some recommendation contexts.
- It provides an intuitive interpretation, as closer points in the embedding space are considered more similar.
The main drawbacks of Euclidean similarity include its unbounded range and sensitivity to the scaling of features.
Advanced Techniques: Pushing the Boundaries of the Two-Tower Model
While the basic Two-Tower model is powerful, several advanced techniques can further enhance its performance:
Hard Negative Mining
Random negative sampling, while simple, may not provide the most informative training examples. Hard negative mining actively seeks out challenging negative examples that the model is likely to misclassify. This technique sharpens the decision boundary and improves overall accuracy.
Implementation involves periodically identifying items that the model incorrectly predicts as highly relevant to a user and incorporating them into the training process. This forces the model to learn more nuanced distinctions between positive and negative examples.
Multi-Task Learning
Expanding beyond simple user-item interaction prediction, multi-task learning incorporates additional related tasks into the model. For example:
- Click-through rate prediction
- Purchase likelihood estimation
- Dwell time prediction
- User satisfaction modeling
By sharing parameters across these related tasks, the model learns more robust and generalizable representations. This approach can lead to improved performance across all tasks and better handling of sparse data scenarios.
Attention Mechanisms
Attention mechanisms have revolutionized many areas of deep learning, and they can significantly enhance Two-Tower models as well. By introducing attention layers within each tower, the model can dynamically weight the importance of different features based on the current context.
For example, in a video recommendation system, an attention mechanism could learn to focus on different aspects of a user's viewing history depending on their current mood or time of day. This dynamic feature weighting allows for more nuanced and context-aware recommendations.
Transfer Learning and Pre-training
Transfer learning techniques can address one of the major challenges in recommendation systems: the cold-start problem. By pre-training the towers on large, general datasets before fine-tuning on domain-specific data, the model can learn useful feature representations even for new users or items with limited historical data.
This approach has shown particular promise in domains like e-commerce, where general product categories and user behaviors can be learned from vast datasets before adapting to specific product lines or niche markets.
Real-World Applications: The Two-Tower Model in Action
The versatility of the Two-Tower model has led to its adoption across various industries:
E-commerce Product Recommendations
Online retailers leverage Two-Tower models to match users with relevant products based on browsing history, purchase patterns, and demographic information. The model's ability to handle large-scale data makes it particularly suitable for platforms with extensive product catalogs.
For instance, Amazon's recommendation system, which drives a significant portion of their sales, employs similar embedding-based techniques to provide personalized product suggestions across millions of items and users.
Content Streaming Personalization
Streaming giants like Netflix and Spotify use Two-Tower-inspired architectures to suggest movies, TV shows, or music tailored to individual tastes. These systems process vast amounts of user interaction data, content metadata, and even audio/visual features to create highly accurate content recommendations.
Netflix's recommendation system, which saves the company an estimated $1 billion per year through increased retention, relies heavily on embedding-based approaches similar to the Two-Tower model.
Social Media Content and Connection Recommendations
Platforms like Facebook and LinkedIn employ Two-Tower-like models to recommend friends, posts, or groups that align with a user's interests and network. These systems must balance personal relevance with network effects and content diversity to maintain user engagement.
Job Matching and Recruitment
Professional networks and job portals use Two-Tower models to connect job seekers with relevant job postings based on skills, experience, and career preferences. This application demonstrates the model's flexibility in handling structured data (e.g., job requirements) alongside unstructured text (e.g., resumes and job descriptions).
News and Article Recommendations
Media companies and news aggregators leverage Two-Tower models to personalize content feeds, balancing user interests with the need for diverse and timely information. These systems often incorporate additional factors like article freshness and trending topics into their recommendation logic.
Challenges and Ethical Considerations
While the Two-Tower model offers powerful capabilities, it's essential to address several challenges and ethical considerations:
The Cold Start Problem
Handling new users or items with limited historical data remains a significant challenge. Techniques like transfer learning and hybrid approaches that incorporate content-based recommendations alongside collaborative filtering can help mitigate this issue.
Scalability and Computational Efficiency
Efficiently computing similarities for millions of users and items requires careful system design and optimization. Techniques like approximate nearest neighbor search and distributed computing are often employed to make large-scale Two-Tower models feasible in production environments.
Explainability and Transparency
As with many deep learning models, the inner workings of Two-Tower systems can be opaque. Developing methods to interpret and explain recommendations is crucial for building user trust and allowing for system refinement.
Fairness and Bias Mitigation
Recommendation systems can potentially amplify existing biases present in the training data. Ensuring fair representation and avoiding the creation of harmful filter bubbles requires ongoing research and the development of bias detection and mitigation techniques.
Privacy Concerns
The collection and use of user data for personalization raise important privacy considerations. Techniques like federated learning and differential privacy are being explored to enable personalized recommendations while preserving user privacy.
The Future of Two-Tower Models in Recommendation Systems
As the field of recommendation systems continues to evolve, we can anticipate several exciting developments in Two-Tower models:
Integration with Graph Neural Networks
Incorporating graph structures into Two-Tower models can capture complex relationships between users and items. This approach is particularly promising for social recommendation scenarios and for modeling intricate item-item relationships.
Federated Learning for Privacy-Preserving Recommendations
As privacy concerns grow, federated learning techniques allow for training Two-Tower models across decentralized data sources without sharing raw user data. This enables personalization while maintaining strong privacy guarantees.
Multimodal Representations
Future Two-Tower models will likely incorporate diverse data types (text, images, video, audio) into unified embeddings. This multimodal approach will enable more holistic and nuanced recommendations, particularly in content-rich domains like entertainment and education.
Dynamic and Contextual Embeddings
Advanced Two-Tower models will adapt user and item representations in real-time based on contextual factors like time, location, and current user activity. This dynamic approach will allow for more responsive and situationally aware recommendations.
Reinforcement Learning Integration
Combining Two-Tower architectures with reinforcement learning techniques can enable recommendation systems that optimize for long-term user satisfaction and business objectives, rather than just immediate click-through rates.
Conclusion: Harnessing the Power of Two-Tower Models
The Two-Tower model represents a significant leap forward in the field of personalized recommendation systems. Its elegant architecture, combining deep learning with efficient similarity calculations, enables scalable and accurate recommendations across diverse domains.
As we've explored, the power of the Two-Tower model lies not just in its basic structure, but in the potential for advanced techniques like hard negative mining, multi-task learning, and attention mechanisms to push its capabilities even further.
For data scientists and machine learning engineers working on recommendation problems, the Two-Tower model offers a flexible and powerful framework. When implementing these models, remember to:
- Carefully consider your choice of similarity metric based on your specific use case and data characteristics.
- Experiment with advanced techniques to enhance performance and address domain-specific challenges.
- Stay mindful of ethical considerations, including fairness, privacy, and the potential for bias amplification.
- Consider the computational requirements and scalability aspects when deploying Two-Tower models in production environments.
As the digital landscape continues to evolve, personalized recommendations will play an increasingly central role in shaping user experiences. The Two-Tower model, with its balance of simplicity and effectiveness, is poised to remain a cornerstone of this personalization revolution. By mastering this approach and staying attuned to ongoing developments in the field, data scientists and engineers can build recommendation systems that truly understand and cater to individual user preferences, creating more engaging and valuable digital experiences for users across the globe.
{kind=link}