
Are you a Python developer looking for ways to scrape leads off LinkedIn for your marketing operations? Whatever you want to scrape from LinkedIn, you can be done using Python. Read the article below to learn how to get that done.
LinkedIn is the social networking platform for professionals. This platform is known for its B2B business opportunities as well as networking. It also does have a job posting service where businesses post their job offering, and you can either apply on the platform or off-platform. If you’re a professional looking to generate leads for your business or just want to scrape job listings, there is a chance you do have LinkedIn on your watchlist. There is just a whole lot of databases you can generate from the platform.
However, doing so manually can be time-wasting, prone to errors, and sometimes impossible if the amount of data to be collected is much. This has led to the growth in automated web data extraction, known as web scraping. With this, you are able to collect data from LinkedIn via automated means. As a Python developer, you can code your own LinkedIn scraper to collect leads from LinkedIn with the right libraries and framework. This article will focus on that.
An Overview of LinkedIn Scraping

LinkedIn scraping is the process of using automated tools known as web scrapers to extract data publicly available on the LinkedIn platform. These web scrapers for LinkedIn can also be called LinkedIn scrapers. The process involved in scraping LinkedIn can be divided into 2, all of which can be implemented using Python. The first process is sending a web request to download the content of a web page, and then the second process is parsing the required data. While web scraping can be easy depending on your target, you have to pay close attention if LinkedIn is your target.
LinkedIn is not an easy target to scrape. In fact, no web scraping legal discussion is ever complete without the mention of LinkedIn. The site vehemently fights against web scraping, and even though it has lost its cases against web scrapers, including the popular HiQ Labs case. LinkedIn has anti-bot and anti-scraping systems in place to discourage scraping. You will need to incorporate anti-blocking techniques and tools to be able to circumvent the checks of LinkedIn in other to scrape it. This even becomes more difficult for you as a coder developing a LinkedIn scraper from scratch.
What Data Can You Scrape from LinkedIn

You already have the kind of data you want to collect from LinkedIn. But have you ever wondered about the kind of data that can be scraped from the platform? Below are some of the popular data collected from LinkedIn on a daily basis.
- Lead: Being a professional social network, LinkedIn is one of the best places to scrape potential leads. You can scrape details of profiles like names, places of work, and even emails for some users. For users that whose emails are not available on their bio, you can follow through to their other social media profiles mentioned to get to them.
- Job Posting: If you are looking for a place where real people post jobs, that place has got to be LinkedIn. A lot of jobs are posted on the platform, and as a job seeker looking to automate the process of applying for a job, you could develop a web scraper that alerts you if there is a job that matches your requirement. Job post scraping is perfect for automated job boards.
- Post Scraping: Being a social media network, users post a whole lot of guides, reviews, and sentiments on the platforms. There are also associated comments that accompany these posts. With the help of a web scraper, you can collect these data and run analysis such as sentimental analysis on the text scraped.
Tools for Scraping LinkedIn Using Python

As a Python programmer, you can easily develop your own LinkedIn scraper. This is because there are existing tools that do the heavy lifting for you — yours is just to tweak them to get what you want. In this section of the article, we will be taking a look at the tools required for scraping data from LinkedIn.
- Requests and Beautifulsoup: While some pages require Javascript rendering on LinkedIn, some pages do not. For pages that can be accessed without Javascript, requests and Beautifulsoup are the best tools to scrape them. Requests is an HTTP library for downloading web pages, while Beautifulsoup is for extracting the needed data from the web page.
- Selenium: Selenium is the de facto Python tool for automation on sites that depends on JavaScript for rendering. The Selenium web driver is a tool that automates web browsers. And according to the copy on their website, what you do with that is up to you. In our own case, we need it to access and render the content of a LinkedIn page in other to scrape it. It can be used to automate Chrome, Firefox, Edge, and a few other popular browsers.
- Proxies: Anytime you need to send many requests within a short period of time, you need to prepare for a block, as websites do not like being bombarded with requests. Proxies are used for getting multiple IP addresses so that the requests will appear as if they are from separate devices. For LinkedIn, you need high-quality mobile proxies to be able to successfully scrape the data you need.
- Captcha Solver: As stated earlier, Linked has a very strong anti-spam system that detects bots. One of the ways LinkedIn discourages bots is by forcing Captchas on suspicious traffic. You might not need to make use of a Captcha solver for the beginner. However, if you start getting Captchas, then you are better off making use of a Captcha solver to bypass the Captchas.
Steps to Scrape LinkedIn Using Python and Selenium
In this section, we will move to the actual coding. I want us to play safe here. While web scraping is legal, this is only true for public pages. For you to scrape LinkedIn profiles, you will need to stay logged in. On top of this, you will need to render JavaScript too. The data we will be scraping that does not require logging in and, therefore, keeping things legal is the job on Linkedin. Below are the steps to scrape Job listings and the companies that post them.
Step 1: Installing Python and Necessary Libraries
Before you can start coding, you need to have python and the necessary libraries installed. For the data we will scrape from the LinkedIn website, all we need to install includes requests and Beautiful. We do not need Selenium even though it can be used.
Python
As a Python programmer, you should already have Python installed on your computer. If you do not, head over to the official download page to download and install the latest version of Python. Python is available for most popular Operating Systems, including Android.
Requests
As stated earlier, Requests is an HTTP library that simplifies the process of handling HTTP requests. This library is not available in the Python standard library, and as such, you need to install it. You can use the pip install command in your command prompt to install it. To do so, type “pip install requests”
Beautifulsoup
Beautifulsoup is the other piece of the puzzle that completes the requests above. While requests download a web page, Beautifulsoup extracts the required data from the web page. It is important you know that Beautifulsoup is not a parser on its own — it utilizes either the default HTML parser that comes in the Python standard library or a third-party parser with lxml as the popularly used option. To install Beautifulsoup, use the “pip install beautifulsoup4” command in your command prompt.
Step 2: Inspect Job Search Page to Find Important HTML Elements
For you to scrape data from a page, you must understand the structure of the page. HTML is the language for defining the structure of web pages. It is made of elements each with its own use and styling to make it look visually appealing. Data on web pages are hidden in HTML elements. For you to scrape, you need to inspect the LinkedIn Job page and see the structure. In this case, the URL we will be scraping from is — https://www.linkedin.com/jobs/search.
The task here is to scrape the job titles and companies with the openings. Nothing fancy, and we won’t be visiting the main page for each of the listings, just a proof of concept. Let’s inspect the page and see the elements containing the job titles and companies.
To inspect elements on a page, right-click on the page and click on “Inspect”. I am using Chrome here; the step might differ in your own case. Below is the screenshot of what the screen looks like with the insect tool.
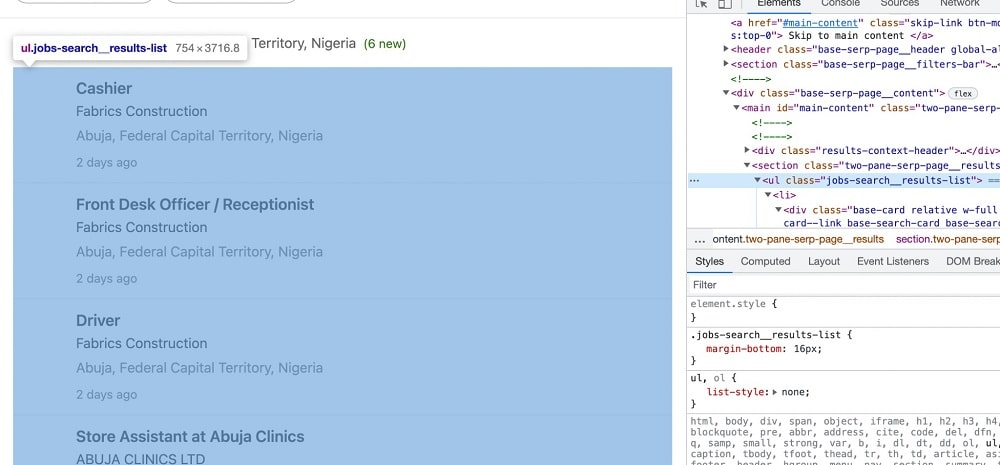
As you can see above, jobs are contained in a ul <ul> element, which is the tag used for unordered lists. The class for this list element is “job-search_results-list”. Each of the job listings is contained in a list element with the <li> tag. Both the job title and company names are contained in a nested element within the <li> elements.
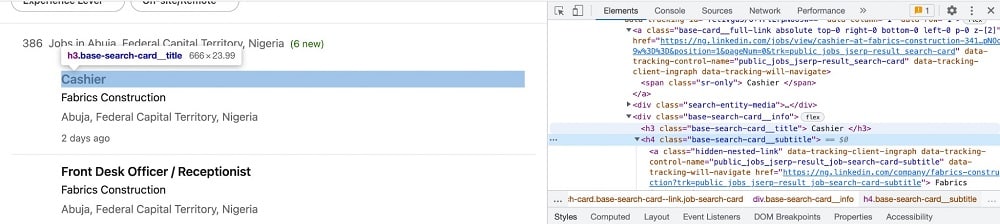
The job title is contained in an h3 element with the class name, “base-search-card__title”. For the company name, you can find it in an h4 element with the class name, “base-search-card__subtitle”.
Step 3: Start Coding the Web Scraper
With the web page inspected and all of the elements that embed the data of interest identified, it is now time to start coding. The first step is to send a web request for the page, download all of the content of the page, and print it on the screen. The code below does that.
import requests
from bs4 import BeautifulSoup
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
job_board_URL = "https://www.linkedin.com/jobs/search?"
response = requests.get(job_board_URL, headers=HEADERS)
soup = BeautifulSoup(response.content)
print(soup)As you can see above, we imported both requests and Beautifulsoup. LinkedIn will not allow web requests with generic user agents to pass through. This is why we added the user agent of Chrome to make our LinkedIn scraper appear to be a Chrome browser. The response variable holds the content of the page downloaded, while the soup variable converts the response into a soup object.
Step 4: Parse Out Job Details
Since the content of the full page has been fed into Beautifulsoup, we can now go ahead and parse out the required details. For some reason, the page might be without the jobs showing. For this reason, the parsing logic is enclosed within a try—except statement.
try:
i = soup.select(".ajob-search_results-list")[0]
jobs = i.find_all("li")
for job in jobs:
job_title = job.find("h3", class_="base-search-card__title")
job_company = job.find("h4", class_="base-search-card__subtitle")
print([job_title, job_company])
except AttributeError:
print(" An error has occurred")As you can see above, we used the elements finder method (find_all()) to get all of the job containers, then use the for loop to loop through each of the jobs. Using the element class for the job title and job company name gotten earlier, we are able to scrap the name and title for the job. As you can also see, we didn’t really handle any exceptions. The only exception we try to catch and handle is attribute error. Even that, we only print a message on the console.
Step 5: Restructure the Code
The code above works. However, looking at the code, you can see. That you can’t defend the job title of interest. A better way to do this is to feed the keyword for the kind of job you are looking for. We’ll do this by converting the code into a function.
from bs4 import BeautifulSoup
def scrape_linkedin(keyword):
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
job_board_URL = "https://www.linkedin.com/jobs/search?keywords=" + keyword
response = requests.get(job_board_URL, headers=HEADERS)
soup = BeautifulSoup(response.content)
try:
i = soup.select(".ajob-search_results-list")[0]
jobs = i.find_all("li")
for job in jobs:
job_title = job.find("h3", class_="base-search-card__title")
job_company = job.find("h4", class_="base-search-card__subtitle")
print([job_title, job_company])
except AttributeError:
print(" An error jas occurred")Improvement to the Code
While the code above works, you need to know that it is nothing but a proof of concept. You can’t use the code above in a production environment or for anything serious. However, with the code above, you have a base and can see that you can collect data from LinkedIn easily. First, the code above does not even specify a location. This means that the US is used as your location. Most job searches actually have a locational requirement and incorporating that into the code will make it more useful. Also important is the fact that the script does not really handle most of the errors that may occur, and the data collected is only printed on the screen, not stored in a file or database. All of these and many more should be taken care of from your end.
It is also important you know that blocks are a must for you if you try scraping LinkedIn, except you put in place measures to bypass the LinkedIn anti-spam system. You will need to improve the code to rotate proxies and solve the LinkedIn captcha.
How to Scrape LinkedIn Using Already-made Python Amazon Scraper
For the most part, you do not need to develop a custom LinkedIn scraper from scratch. This is because there are already-made web scrapers out there that you can use. As a Python developer, there is a lot of option for you. You can check GitHub and other similar services to get LinkedIn scraper to use.
However, we recommend you make use of paid LinkedIn scraper like the one provided by Apify. This is because web scrapers on Apify are effective and get regular updates to avoid blocks and improve performance. Apify provides a good number of LinkedIn scraper ranging from company URL finder to people finder. Below is how to use the LinkedIn People finder.
Step 1: Go to Apify and register for an account. You will be given an API CODE which you will use for authentication.
Step 2: Use the “pip install Apify-client” command in your command prompt to install the Apify client for python.
Step 3: Run the code below provided by Apify to see how to make use of the Apify Linked People Finder scraper.
from apify_client import ApifyClient
client = ApifyClient("<YOUR_API_TOKEN>")
run_input = { "queries": "John Malkovich" }
run = client.actor("anchor/linkedin-people-finder").call(run_input=run_input)
# Fetch and print actor results from the run's dataset (if there are any)
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(item)Even though the tool is a paid tool, new users are allowed to use it for free for 3 days so you do not need to subscribe in other to make use of the service.
How to Scrape LinkedIn Using Python Web Scraping APIs
LinkedIn being very effective at blocking bots is something to worry about. Sometimes, there is just nothing you can do about it — you will still get blocked. If you keep getting blocked while trying to scrape LinkedIn, it is time to give up and delegate the job to a web scraping API. LinkedIn Web scraping APIs help you focus on what to do with LinkedIn data rather than how to collect the data. They handle proxies, captchas, and all other blocking systems.
With a web scraping API, all you have to do is send a simple API request with the URL of the LinkedIn page and its parameters, and you get either the full HTML of the page or the required data as JSON in return. There are a good number of web scraping APIs that support python. However, we recommend Crawlbase, ScraperAPI, and ScrapingBee because of their effectiveness.
FAQs
Q. What is LinkedIn Scraping?
LinkedIn scraping is the process of using a web scraper to extract data publicly available on the LinkedIn platform. This is an automated process, making it fast. The method is used for generating leads, scraping jobs, and other details from the platform. If you are a coder, you can develop a web scraper that scrapes LinkedIn, provided you know how to send requests, parse data of interest, and avoid blocks. There are also some tools made readily available that make it easier for those that do not know how to develop web scrapers from scratch.
Q. Does LinkedIn Allow Scraping Data from It Platform?
LinkedIn does not allow the scraping of data from its platform. In fact, the most popular web scraping lawsuit of all time has LinkedIn involved. LinkedIn currently has one of the most difficult-to bypass-anti-bot systems. This makes it difficult for web scrapers to scale through. You even require mobile proxies in some cases to successfully scrape LinkedIn. However, this does not mean scraping it is illegal. You can scrape publicly available data with no problem. The major issue is if you scrape data hidden behind passwords.
Conclusion
Make no mistake about it, scraping LinkedIn is not an easy job to do. However, as a Python developer, you are at an advantage. There are tools out there that make it easier for you to develop LinkedIn scraper in Python than in any other programming language out there. However, you need to know that LinkedIn is very effective at detecting bot traffic and, as such, must integrate measures to avoid detection and ban.
{kind=link}