
Scraping product data from Amazon can be rewarding and help you make informed marketing decisions as a marketer. In the article below, we will be taking a look at how to collect data from Amazon via web scraping using Python.
The web is one of the largest sources of business in the world today. And when it comes to e-commerce data, there are a good number of sources out there.
There is Amazon, AliExpress, eBay, Walmart, and hundreds of thousands of others available. Amazon, however, is the number one e-commerce platform accounting for 56.7 percent share of US e-commerce sales.
You can possibly purchase all of your daily needs on the platform. It is basically the Google of e-commerce. The share number of product data and user-generated data in terms of review makes it a good target for marketers interested in scraping product-related data.
But how easy is it to scrape data from the Amazon platform? Do you know how to code in Python? With a skill in Python programming, you can easily scrape data from Amazon depending on the magnitude of the data you want to collect. In this article, we will show you how to scrape Amazon products using Python.
An Overview of Amazon Scraping
Amazon scraping is the process of using specialized automation bots known as web scrapers to automatically extract publicly available data from the Amazon website.
The manual process of collecting data can be tedious, trying, error-prone, and sometimes even impossible if you need to collect data at scale. The only major option that is affordable is to automate the whole process using a bot. Bots that can collect data from Amazon are known as Amazon scrapers.
While many of them are general-purpose scrapers that can be used for scraping data from other platforms, some are highly specialized, meant for only scraping data from Amazon.
As with other popular web platforms, Amazon does not support the use of bots on their platform, such as web scrapers. They have got systems in place to discourage the scraping of data from their platforms.
For already-made web scrapers, this has already been taken care of. However, if you want to develop a custom scraper for Amazon, you will have to take care of this from scratch. Only when you are able to bypass the Amazon anti-spam system will you be able to scrape data from the platform.
What Data Can You Scrape from Amazon
To the untrained eyes, Amazon only contains product data. However, if you are experienced, you can tell that there is a lot of data of interest on the platform. Below are some of the classes of data that can be collected from the platform.
- Product Data: There are about 350 products for sale on Amazon. This is the largest inventory of product data you can get on the Internet. You can find anything from air fryers to groceries. Data of interest in this category include Asin, price, images, description, best seller rank, and star rating.
- Customer Review Data: As a seller on Amazon, you will want to know the sentiment toward your products. Are the verified buyers happy with the products? Do they break easily, or are quite durable? All of these and many more are revealed in consumer reviews, and manufacturers and sellers scrape this to gain insight to know the reception and what customers think about the product.
- Ranking Data: This is applicable only to sellers on Amazon. If you want to know how well your product rank on the Amazon Search Result Pages, then you will need to scrape it. Ranking changes and you might want to keep a tab on your ranking and that of your competitors to know if your current strategy is working.
Tools for Scraping Amazon Using Python

As stated earlier, you could develop your own scraper for Amazon or use an already-developed one. Those with Python coding knowledge are in a better position to develop their own scraper because of the libraries and frameworks available for scraping. As a Python coder looking to scrape Amazon, you need the following tools.
- Requests and BeautifulSoup: These two libraries are starter kit libraries for scraping. Fortunately for us, Most content on Amazon does not require Javascript rendering. Requests is the HTTP library for sending web requests, while BeautifulSoup is the library that makes extracting data from web pages easy. For data that require JavaScript rendering, Python developers will need to use selenium WebDriver.
- Proxies: Amazon does not allow the scraping of its content and has an anti-bot system in place to stop you. Sending too many requests from the same IP address within a short period of time will reveal you to be a bot. You will need to make use of proxies. But not all proxies will work for Amazon. You need to use high-rotating residential proxies that are undetectable. We recommend you make use of residential proxies from Bright Data, Decodo, Proxy-Seller, or Oxylabs. With the right proxies, you should evade their IP tracking and blocking system.
- Captcha Solver: You might not need a Captcha solver, depending on how you are able to remain under the radar. Amazon uses CAPTCHA to stop bots. Once an Amazon captcha appears, you will need to solve it to continue scraping. There are many options, including paid options. However, we recommend you check Github; there are many free captchas you can use to solve Amazon captchas. As a head-up, you can check out the Amazon-captcha-solver on Github. There is also another one on the Pypi platform.
Steps to Scrape Amazon Products Data Using Python
In this section of the article, we will be taking a look at how to use Python for coding a web scraper for extracting product details from the Amazon website.
The bot is going to be pretty basic and somewhat like a proof of concept to show you how it is done. The product page does not depend on Javascript to work, making it perfect for scraping using the duo of Requests and Beautifulsoup. Below are the steps to follow to code a Python Amazon web scraper.
Step 1: Install Necessary Libraries
For this particular exercise, you need only Python, Requests, and Beautifulsoup. Let’s see how to install each of these below.
Python
Python is the most important of all the tools needed as it is the programming language used. There is a Python installation that comes with most computers (Python 2). This is not the version required. You need to install the latest version of Python 3. Download and install it from the official download web page for security purposes. It is available for Windows, macOS, Linux, and iOS, among others.
Requests
With Python installed, you can now move to install the third-party libraries for scraping. Requests is an HTTP library that simplifies sending of HTTP requests. It is more robust and easier to use than the “urllib.request module” that comes in the Python standard library.
Beautifulsoup
While Requests is used for sending requests to download web pages from Amazon, Beautifulsoup is used for extracting specific data points from the web pages. It is not necessarily a parser, as you can use a parser of your choice under the hood. What it does is use the parser to traverse the page and collect the required data. Use the “pip install beautifulsoup4” command to install it.
Step 2: Inspect The Product Page
While others will want to start coding, I prefer to inspect a web page to get the IDs and classes of the important data point so that coding will become a lot easier. Since I am interested in the product data, such as product name and price, I will have to focus my inspection on them.
To inspect the HTML of a webpage, access the page and, right-click, then click on the “Inspect”. I am using Chrome here. The step may vary depending on your browser. We will be taking a look a the element that contains the important data points of interest. Use the arrow button to click on the element, and you will see the element’s HTML code.
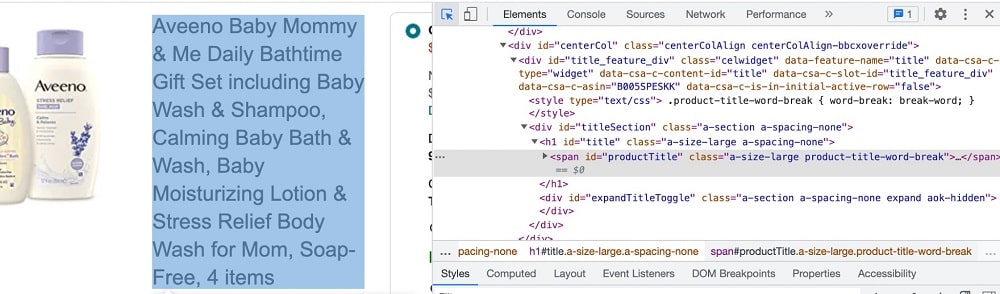
As you can see from the above screenshot, the name of the product is embedded in the span element with the ID value “productTitle”. For the price, there is some form of nesting involved. We can use the span element with the class value “apexPriceToPay” you can see the screenshot below.
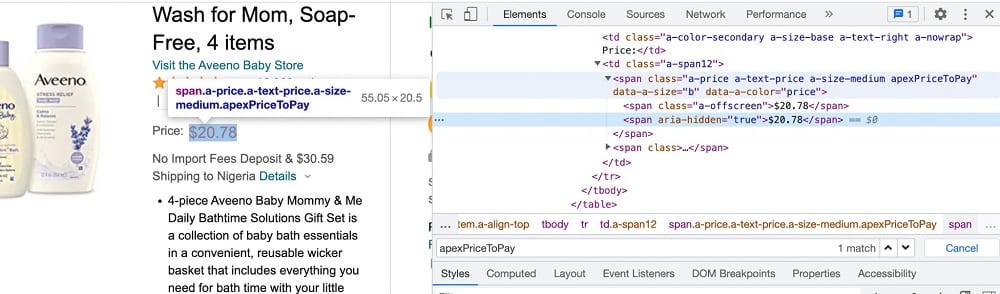
Step 3: Start Coding the Web Scraper
With the element settled, you can now start coding your scraper. Create a new python file
from bs4 import BeautifulSoup
import requests
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
product_URL = "https://www.amazon.com/Aveeno-Baby-including-Moisturizing-Soap-Free/dp/B005SPESKK/"
webpage = requests.get(product_URL, headers=HEADERS)
soup = BeautifulSoup(webpage.content)The code above downloads the web page of the product on Amazon and feeds it to the soup variable, which is a Beautifulsoup object ready for extraction. From the beginning of the code, you can see both requests and Beautifulsoup were imported. For the headers, you will see that two important headers were added — user-agent and language.
It is important you know that without the user-agent header, you can’t scrape from Amazon. The default user-agent of a script written with Requests is something like “python-requests/2.25” — this is blocked by default by the Amazon anti-spam system as no browser or manual user agent uses such.
Step 4: Parse Out Product Details
If you run the code above and add the print function with “soup” as the variable, the raw HTML of the product page. But we are not interested in all of these.
All we want is to extract specific details from the page. Already, the raw HTML has been fed to the soup object, which makes it easy for us to traverse it to get our required data. As at the time we inspected the HTML of the page in step 2, the product name is embedded in span with “productTitle” as value. For the product price, you can get it in another span element with “apexPriceToPay”.
# Extract product name
try:
product_name = soup.find("span", attrs={"id": ‘productTitle'}).text.strip()
print(product_name)
except AttributeError:
print("NA")
# Extract product price
try:
product_price = soup.select(".apexPriceToPay")[0].text
print(product_price)
except AttributeError:
print("No price for this product")We only try to catch an attribute error should the name or price does not exist. Even at that, the code is to continue gracefully with our breaking. Other kinds of errors will definitely break the code and get the bot to stop.
Step 5: Restructure the Code
The code above works, but just displaying the product details on the screen is not enough, we need to either use the data or store it in a database to be used later. Also, it is more practical that we will be scraping multiple products. Let’s make changes to the code to reflect these.
from bs4 import BeautifulSoup
import requests
def Amazon_scraper(product_url):
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
webpage = requests.get(product_url, headers=HEADERS)
soup = BeautifulSoup(webpage.content)
File = open("products.csv", "a")
# Extract product name
try:
product_name = soup.find("span", attrs={"id": 'productTitle'}).text.strip()
#add product name to products.csv
File.write(f"{product_name},")
except AttributeError:
print("NA")
# Extract product price
try:
product_price = soup.select(".apexPriceToPay")[0].text
print(product_price)
# add product price to products.csv
File.write(f"{product_price},\n")
# closing the file
File.close()
except AttributeError:
print("No price for this product")
product_URLs = ["https://www.amazon.com/dp/B005SPESKK"
"https://www.amazon.com/dp/B001PB8FX2",
"https://www.amazon.com/dp/B002UQW8OS"
]
for url in product_URLs:
Amazon_scraper(url)Improvement to Make to Python Amazon Scraper Above
Looking at the code above, you can tell that it works. However, it is bound to break more than it will work if you try using it in a production-level environment.
This is because we only try to handle one exception, and even at that, it is handled in such a way that the code will continue running — nothing serious was actually implemented. Also, the code does not include any form of anti-bot bypass technique.
For you to effectively scrape Amazon, you will need to integrate proxies and rotate them at random intervals to avoid generating patterns that can be used to detect your activities.
Also, Amazon depends on captchas to keep the web both away. The moment the anti-bot system is triggered, you are forced to solve captcha. To improve the code, you need to handle common possible exceptions and integrate anti-blocking systems such as proxies and an Amazon captcha solver.
How to Scrape Amazon Using Already-made Python Amazon Scraper
As a Python developer, you must not reinvent the wheel as far as scraping Amazon product data is concerned. There are a good number of Amazon web scrapers that you can integrate into your code to scrape Amazon in simple steps. You can find these scrapers on Github to use for free. However, if you are looking for a solution that has been built to be robust and is almost always maintained, then using the Amazon scraper on Apify is the best. Below is how to make use of the Amazon product scraper on the Apify platform.
Step 1: Visit the official website of Apify and access the Amazon product scraper URL here.
Step 2: This web scraper is a paid tool, but you can get started for free. Click on the Try for Free button.
Step 3: This will take you to the signup page, where you are required to register in other to use the free plan to try out the service.
Step 4: Use the “pip install apify-client” command to install the Apify client. You will need it to run all of the actors on the Apify platform, including the Amazon product scraper.
Step 5: Use the below code example to learn how to use the Python client provided by Apify to scrape Amazon products without you thinking of developing your own scraper from scratch.
from apify_client import ApifyClient
# Initialize the ApifyClient with your API token
client = ApifyClient("<YOUR_API_TOKEN>")
# Prepare the actor input
run_input = {
"categoryOrProductUrls": [{ "url": "https://www.amazon.com/s?i=specialty-aps&bbn=16225009011&rh=n%3A%2116225009011%2Cn%3A2811119011&ref=nav_em__nav_desktop_sa_intl_cell_phones_and_accessories_0_2_5_5" }],
"maxItems": 100,
"proxyConfiguration": {
"useApifyProxy": True,
"apifyProxyGroups": ["RESIDENTIAL"],
},
}
# Run the actor and wait for it to finish
run = client.actor("junglee/amazon-crawler").call(run_input=run_input)
# Fetch and print actor results from the run's dataset (if there are any)
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(item)How to Scrape Amazon Products Using Python Web Scraping APIs
Using Apify is a good alternative to developing your own scraper. But sometimes, Apify could get blocked even with proxies used.
If you are scraping at scale and do not want to deal with blocks and captchas, then you will need to make use of a web scraping API.
With web scraping APIs for Amazon, you only need to send a simple web request, and you get back, as a response, a JSON with the product details. Popular web scraping APIs, including ScraperAPI, ScrapingBee, and Crawlbase, all do have support for Amazon product scraping.
FAQs
Q. What is Amazon Scraping?
Amazon scraping is the process of using an automation bot known as an Amazon scraper to extract publicly available data from Amazon web pages.
The data of interest on the Amazon e-commerce store includes product details like price, description, rating, and images, as well as customer review data.
These are incredibly important to marketers and manufacturers as they provide a clue as to how well their customers like or dislike their products. Amazon scrapers are also used by marketers on the platform to monitor their ranking on Amazon product search pages.
Q. Does Amazon Allow Scraping?
As with most popular web services on the Internet, Amazon does not permit the scraping of data from its platform. The service even discourages the use of bots of any kind, with scrapers as the most hated among them.
It does have anti-bot and anti-scraping systems in place to block web scrapers. Only when you are able to bypass these will you be able to scrape data from their platform.
However, it is important you know that while Amazon discourages the use of scrapers on their platform, this does not make it illegal. This is especially true if you are scraping publicly available data.
Q. What are the Best Ways to Avoid Blocks While Scraping Amazon?
The anti-spam system of Amazon is quite smart. This means that the average bot will not scan true after a few attempts. For you to scrape Amazon successfully, you will need to integrate anti-blocking systems and techniques into your code and do so intelligently.
Some of the best ways to avoid blocks are to make sure you set your user agent to that of a popular browser and use rotating proxies. It is important you set random delays between requests and use captcha solvers if you keep getting captchas.
Conclusion
Looking at the above, you can see that scraping Amazon using Python is easy if you know what you are doing. While creating your own Amazon scraper with python is the most notable method of getting that done, there are other methods, such as using an already-made Amazon scraper as well as using a web scraping API.
The last two methods take a lot of burden off you as you will not have to deal with managing the scrapers, which is one of the most difficult things to do if you web scrape often.

{kind=link}